Discussing advanced techniques for optimizing global memory access and dataflow in FPGA HLS designs, including AXI protocol, DDR structure, and HLS pragmas.
Advanced FPGA HLS: Memory Access and Dataflow Optimization
众所周知, 在加速器设计中, 无论是 CPU, GPU 还是 FPGA, 全局内存访问的优化都是一个很令人头疼的问题. 一方面由于内存 (DRAM) 的硬件结构, 决定了它只有在顺序访问的时候才能发挥最大的带宽, 况且由于加速器计算单元通常具有超高的并行度, 对内存带宽和延迟的要求也非常高; 另一方面是算法五花八门, 内存访问模式也不尽相同, 很难有一种通用的优化方法. 多级 Cache 是 CPU 和 GPU 解决这个问题的主要手段, 而 FPGA 则更多依赖定制数据路径和硬件流水化来缓解这个问题. 这里我们不过多讨论如何适配算法设计最好的数据路径, 只讨论怎么尽快将数据从全局内存读入到片上的 BRAM 或者 URAM 中, 又怎么将计算结果尽快写回全局内存.
AXI 协议
在 FPGA 设计中全局内存基本都是通过 AXI 协议来访问. 例如通过 AXI4-Full 接口可以提供按地址随机读写的能力, 而 AXI4-Stream 则提供了更高效的流式数据传输能力. 首先看看 AXI4 协议的读写流程.
AXI4-Full 有五个独立的通道, 每个通道都有对应的握手信号 (READY 和 VALID). 这五个通道分别是读地址通道 (AR), 读数据通道 (R), 写地址通道 (AW), 写数据通道 (W) 和写响应通道 (B). 所有动作发生的前提都是发送方设置 VALID 信号, 接收方设置 READY 信号, 且双方同时为高时数据传输才会发生.
首先是发送过程.
- Master 端在 AW 通道上设置好地址, 突发长度 (Burst Length), 突发大小 (Burst Size) 等信息后拉高
AWVALID, Slave 端准备好接收后拉高AWREADY, 地址传输完成. - Master 端在 W 通道上放置好数据, 拉高
WVALID, Slave 端准备好接收后拉高WREADY, 数据传输完成. 如果是突发传输, 则 Master 端需要连续发送多次数据, 每次数据传输完成后都需要等待 Slave 端拉高WREADY信号. 最后 Master 端在最后一次数据传输时拉高WLAST信号, 表示突发传输结束. - Slave 端在 B 通道上放置好写响应信息, 拉高
BVALID, Master 端准备好接收后拉高BREADY, 写响应传输完成.
读过程也是类似的.
- Master 端在 AR 通道上设置好地址, 突发长度 (Burst Length), 突发大小 (Burst Size) 等信息后拉高
ARVALID, Slave 端准备好接收后拉高ARREADY, 地址传输完成. - Slave 端准备好第一个数据, 放在 R 通道上, 拉高
RVALID. Master 端准备好接收后拉高RREADY, 数据传输完成. 如果是突发传输, 则 Slave 端需要连续发送多次数据, 每次数据传输完成后都需要等待 Master 端拉高RREADY信号. 最后 Slave 端在最后一次数据传输时拉高RLAST信号, 表示突发传输结束. - 读没有单独的响应通道, 读响应信息包含在 R 通道上.
这两个过程中, FPGA 端通常作为 Master 端, DRAM 作为 Slave 端, 因为是 FPGA 一方主动发起读写请求. 从这个流程里面不难看出 Burst Length 和 Burst Size 是影响内存访问效率的关键参数. 本科阶段的微机原理课程中讲过 DMA 的块传输 (Block Transfer), 提到过块传输会有更高的效率, 原理是一样的. 在突发传输下, 不需要每访问一个地址都进行一次地址传输, 而是只需要传输一次起始地址, 后续的地址通过突发长度和突发大小来计算得到, 从而降低地址传输的占比. 况且, DRAM 端非常喜欢连续的地址访问, 更容易命中行缓存 (下一节会提到 DRAM 的结构), 也就能提供更高的带宽.
接着看看 AXI-Stream 协议. 相比 AXI4-Full, AXI-Stream 根本就没有地址通道, 也没有响应通道, 只有单向的数据传输能力. 它只有四根重要的信号线: TVALID, TREADY, TDATA 和 TLAST. 其中 TVALID 和 TREADY 是握手信号, TDATA 是数据线, TLAST 用于标记数据流的结束. 由于没有地址和响应通道, 所以显然 AXI-Stream 是完全不能随机读写的, 并且不能直接连接到内存上, 需要通过 MM2S (Memory-Mapped to Stream) 和 S2MM (Stream to Memory-Mapped) IP 核来间接实现内存访问.
AXI-Stream 的传输过程如下.
- Master 端在
TDATA上放置好数据, 拉高TVALID - Slave 端的缓冲只要没满, 就一直拉高
TREADY - 当双方同时为高时, 连续地传输数据. 如果是数据流的最后一个数据, 则 Master 端在该数据对应的时钟周期拉高
TLAST信号.
非常简单, 因此它通常能达到更高的频率和数据位宽 (因为布线相对更简单), 但使用场景比较受限.
DDR 结构简介
在讨论 HLS 设计中的内存访问优化之前, 先了解一下 DDR 的硬件结构. DDR (Double Data Rate) SDRAM 的特点是在时钟的上升沿和下降沿都能传输数据 (所以叫 Double Data Rate). 一些比较新的 DDR4 和 DDR5 还引入了更复杂的预取 (Prefetch) 机制, 以进一步提高数据传输效率.
先看看 DDR 的基本结构. 一块 DDR 芯片通常由多个 Bank 组成, 不同的 Bank 相互独立, 可以并行工作. 每个 Bank 由多个 Row 和 Column 组成. 最基本的储存单元称为 Cell, 一个 Cell 里面储存 1 bit 的数据. 数电课上讲过, Cell 是由电容构成的, 需要定期刷新 (Refresh) 以防止数据丢失. 多个 Cell 组成一个 Column, 多个 Column 组成一个 Row. 每个 Row 通常有几千到几万个 Cell, 具体数量取决于 DDR 的规格和容量. 例如 DDR3-1600 的一个 Row 通常有 8192 个 Cell (8K bits).
进行数据访问的时候, 需要先激活 (Activate, ACT) 一整行 (Row), 通过 Bit Lines 将该行的数据读入到 Row Buffer 中 (这是过程其实是电容略微放电, Row Buffer 通过感应电压变化来更新数据). 之后数据经过 Column Mux, 根据列地址被选择, 并通过 I/O Gating 传输到外部数据总线. 数据传输完成后, 该行可以被预充电 (Precharge, PRE), 以便后续访问其他行. 整体结构如下图所示.
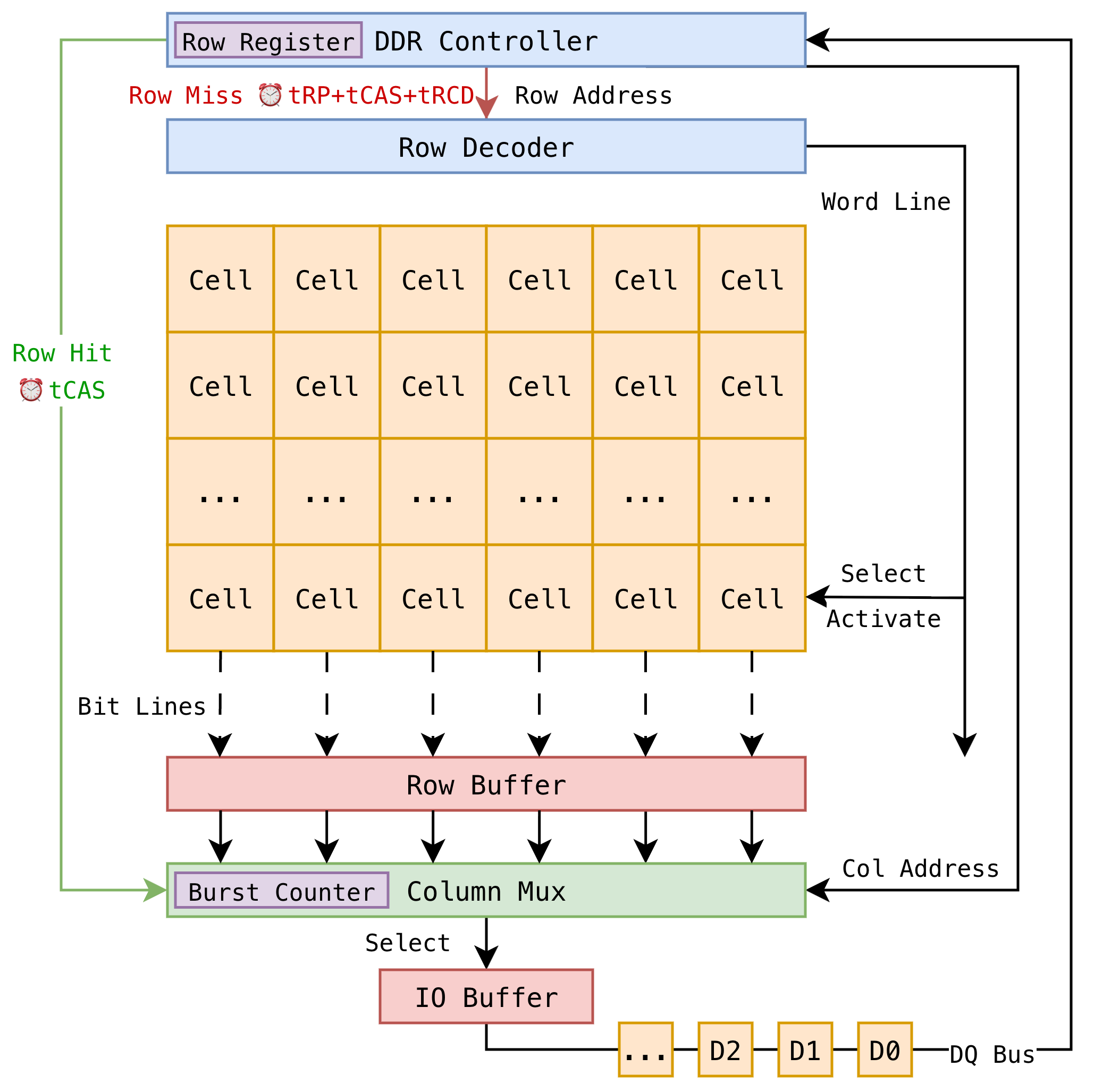
在 DDR 控制器中有一个行寄存器, 储存了当前被激活的行地址. 当有新的访问请求到来时, 控制器会先检查请求的行地址是否和行寄存器中的地址相同, 如果相同则称为 Row Hit, 请求直接发送到 Column Mux 进行数据传输; 如果不相同则称为 Row Miss, 需要先发出 Precharge (PRE) 命令关闭当前行, 然后发出 Activate (ACT) 命令激活新的行, 最后才能进行数据传输. 前者需要的时间即为 tCAS (Column Access Strobe), 后者需要的时间则是 tRP + tRCD + tCAS (Row Precharge + Row to Column Delay + Column Access Strobe). 对于 DDR4-3200 来说, 每一项大概都在 10-15 纳秒左右. 所以很显然, 如果访问模式很随机, Row Miss 的概率就会非常高, 频繁触发 PRE 和 ACT 命令, 导致内存访问延迟直接爆炸.
另外在 Column Mux 里面有一个突发计数器 (Burst Counter), 它根据突发长度 (Burst Length) 来决定每次传输多少数据. 每选出一个 Column, 突发计数器就会更新, 直到达到突发长度为止. 在这个过程中, DDR 控制器不需要每次都重新发送地址, 只是连续地传输数据. 显然这里又省去了一些地址传输的延迟.
以上主要是数据读取的过程, 数据写入的过程基本类似, 只要连续写入相邻的地址就能避免频繁的 PRE 和 ACT 命令, 提高写入效率. 那优化的方向也就很明显了, 尽可能使用顺序访问模式, 同时尽可能增大突发长度.
HLS 设计中的内存访问优化
在 HLS 设计中, 通常顶层模块都是直接通过 AXI 接口和全局内存通信的. Vitis 提供了很多指定 AXI 接口属性的高级选项, 属于 interface pragma 的一部分. 我们讨论一下这些内容.
void kernel(int *mem) { /*...*/ }
#pragma HLS interface m_axi port=mem offset=slave bundle=gmem0 \
max_read_burst_length=... max_write_burst_length=... \
num_read_outstanding=... num_write_outstanding=... \
latency=... depth=...假设有一个顶层函数 kernel, 它通过 AXI4-Full 接口访问全局内存. 上面展示了和 AXI 数据传输相关的几个重要选项.
max_burst_length用来指定最大突发长度, 也就是一次突发传输中最多传输多少个数据, 单位是数据个数 (不是字节数). 前面的讨论已经知道了, 更高的突发长度能够提高内存访问效率, 减少地址传输的开销.num_outstanding用来指定最大超前传输数. 总线内存传输不是瞬间完成的, 通常会占用不少周期. 最 naïve 的方式是每发起一个传输事务都等待完成后再发起下一个事务, 这样总线的 Master和 Slave 会轮流处于空闲状态. 但实际上如果内存访问模式已知, 可以在上一个事务还没完成的时候, 发起下一个新请求, 这样总线上就会有多个在途 (On-the-fly) 事务, 提高总线利用率. 为什么可以这样做呢? 因为 AXI 协议的地址通道和数据通道是独立的, Master 第一个地址发出去之后, 不用等待数据传输结束, 就可以继续发下一个地址. 这种独立设计的另一个好处是允许乱序传输, 后发起的请求可以先完成.latency用来指定内存访问的预期延迟, 单位是时钟周期. 这个参数主要用来帮助 HLS 工具进行调度优化, 让计算单元和内存访问更好地重叠 (Overlap).depth不会影响综合结果, 它是用在 C-RTL Co-sim 里面用来指定这段内存的深度 (单位是数据个数), 以便生成正确的测试平台.
据此, 就有以下几点优化方式
- 对于只读端口,
max_write_burst_length=2, 且num_write_outstanding=1. 这是 Vitis 官方推荐的方式. 因为只读端口对写的要求几乎等于零, 所以把写相关的参数都设置到最小值即可. - 同样对于只写端口,
max_read_burst_length=2, 且num_read_outstanding=1. - 使用
max_burst_length和num_outstanding配合来掩盖访问延迟. 但必须注意的是, 这两个参数的代价是增加 BRAM 使用量. 无论是增加突发长度还是增加超前传输数, 都需要增加总线上的缓冲区大小, 而这些缓冲区几乎只能用 BRAM 实现 (URAM 时序表现比 BRAM 差). 一个简单的原则是带宽延时乘积 (Bandwidth-Delay Product, BDP). 基本思想是, 为了使总线通道不出现空泡 (Bubble), 必须保证"在途"的数据量足以覆盖从发起请求到收到数据的这段延迟. 对于这条 pragma 中的参数, 也就是
- 由于
latency基本只取决于硬件架构 (比如从模块到 DDR 经过了多少级路由), 和算法没有关系, 因此有两个调整方向, 增大max_burst_length或者增大num_outstanding. 对于顺序访问, 一般调大max_burst_length更有效, 因为这种模式对地址通道压力小, Master AXI 实现逻辑简单一些; 对于随机访问, 一般调大num_outstanding更有效, 因为这种模式灵活性更高, 能更好处理地址跳跃带来的问题.
对于本身就是顺序访问模式的算法, 优化通常是更简单的. 例如矩阵乘法, 卷积等, 只要保证突发长度足够大, 一般就能达到接近满带宽的访问效率. 但对于随机访问模式的算法就复杂一些. 大部分的随机访问仍然具有局部性, 也就是说只在一个相对有限的地址范围内跳跃. 这种情况可以利用 BRAM/URAM 做一个片上 Cache, 模块直接从 Cache 读写数据, 而 Cache 模块负责和全局内存通信. 此时 Cache 模块可以将突发传输长度拉满, 触发缓存更新的时候以最大的带宽从全局内存读入一大块新数据. 不过这需要考虑 Cache 的替换策略, 以及 Cache 命中率问题, 相对复杂. 对于局部性较差的随机访问模式, 使用更高的 num_outstanding 就显得作用更大一些了, 配合上一些预测机制, 也能获得不错的访存效率.
对于访问连续的算法, 除了以上参数以外, 还可以通过修改总线宽度的方式进一步提高内存访问效率. AXI 数据总线可以是 32, 64, 128, 256, 512 或者 1024 (对于 DDR 访问不常见) 位宽, 突发长度仅仅是省去了多次地址传输的开销, 但数据传输本身还是逐个数据单元进行的. 如果将总线宽度增大, 一个周期内就能传输更多数据. 不过这需要修改顶层接口, 以及额外添加解码逻辑, 例如
#include "ap_int.h"
constexpr int BUS_WIDTH = 512; // bits
constexpr int DATA_WIDTH = 8; // assuming uint8_t elements
constexpr int ELEMS_PER_WORD = 512 / DATA_WIDTH; // number of elements per 512-bit word
using pkg_t = ap_uint<BUS_WIDTH>;
void fetch_and_dispatch(pkg_t *mem, uint8_t *out_buffer, int n_elems) {
constexpr int N_ITERS = (n_elems + ELEMS_PER_WORD - 1) / ELEMS_PER_WORD;
for (int i = 0; i < N_ITERS; ++i) {
#pragma HLS pipeline II=1
pkg_t word = *mem++;
// dispatch logic
for (int j = 0; j < ELEMS_PER_WORD; ++j) {
#pragma HLS unroll
int idx = i * ELEMS_PER_WORD + j;
if (idx < n_elems) {
out_buffer[idx] = word.range((j + 1) * DATA_WIDTH - 1, j * DATA_WIDTH);
}
}
}
}
void kernel(pkg_t *mem) {
#pragma HLS interface m_axi port=mem ...
uint8_t dispatch_buffer[BUFFER_SIZE];
fetch_and_dispatch(mem, dispatch_buffer, TOTAL_ELEMS);
// further processing...
}在这个例子中会创建一个 512 位宽的 AXI 接口, 每次从内存中读取连续的 512 位数据, 然后拆分成多个 8 位的数据元素存入 out_buffer. 相比原先如果使用 uint8_t* 作为内存接口, 尽管 max_burst_length 可以很大, 但每个周期只有 8 位有效数据, 现在每个周期就有 512 位有效数据, 带宽提升了 64 倍.
但和 DDR 相连的 AXI 总线宽度并非越大越好. 这主要是两个原因导致:
- 总线宽度越大, 布线复杂度越高, 时序越难收敛.
- 有些 FPGA 的 DDR 控制器就到不了那么高的总线宽度, 例如 Zynq 系列的 DDR 控制器集成在 PS 端, PS 端引出两个最大 128 位宽的 FPD 端口给 PL 端使用, 这里硬件就限制了 512 位宽的 AXI 接口无法直接连接到 DDR 上. 而在 Versal 系列上, DDR 控制器作为 PL 端 IP 核, 总线宽度自由一些, 并且 DDR 数据可以直接连到片上 NoC 网络, 而 NoC 网络支持非常高的总线宽度. 如果强制使用超过物理限制的总线宽度, 是需要转接逻辑的, 最终也还是要拆成物理支持的宽度进行传输, 那反而不如直接顶着物理限制的宽度来得简单高效.
数据流优化
几乎所有算法要放到硬件上跑都是 Load-Compute-Store 的结构, 也就是先从内存加载数据到片上, 然后进行计算, 最后将结果存回内存. 并且内存访问和计算完全可以解耦 (Decouple), 也就是说内存访问和计算可以同时进行, 互不干扰. 这就给我们提供了一个很好的优化思路, 那就是通过数据流 (Dataflow) 优化来最大化内存访问和计算的重叠 (Overlap).
在编写 HLS 代码的时候, 首先分析一段算法的内存访问模式, 将其访存操作合并, 尽可能提取到整个流程最开始的阶段, 将计算部分放在整个流程中间, 而写回则可以根据计算中可能有的条件分支提前写回. 这样形成一个 2.5/3 段式 (因为有时候写回和计算可以直接融合) 的 Load-Compute-Store 结构. 将三个部分分别封装成独立的函数, 彼此之间通过 FIFO (如果可以转换成流式计算), 或者 PIPO (双缓冲) 进行数据交换. 然后在顶层模块中使用 dataflow pragma 将三个部分组合起来. 这是实现内存和计算重叠的基本思路. 最终形成例如
void load_data(int *mem, int *buffer, int n) { /*...*/ }
void compute(int *in_buffer, int *out_buffer, int n) { /*...*/ }
void store_data(int *mem, int *buffer, int n) { /*...*/ }
void kernel(int *mem, int n) {
#pragma HLS dataflow
int in_buffer[BUFFER_SIZE];
int out_buffer[BUFFER_SIZE];
load_data(mem, in_buffer, n);
compute(in_buffer, out_buffer, n);
store_data(mem, out_buffer, n);
}这样的结构. 所以将一段算法转换成加速器设计, 重组 Load/Compute/Store 指令的顺序是最重要的一步. 把它们拆开成独立的模块, 有的时候甚至做一些简单的依赖图局部展开 (例如复制一些地址索引计算语句), 尽可能让这些代码之间彼此独立 (除数据交换以外, 中间结果尽可能不互相依赖), 这样才能最大化重叠效果.
另外还有一个小技巧是, 复杂的分支跳转, 尤其是依赖于动态计算结果的分支跳转, 编译器未必能成功实现 Dataflow 调度, 这个时候可以做一些变换, 例如统一分支路径的长度, 让每条路径都执行相同数量的计算 (如果这些额外的计算不太昂贵), 再比如用 Mux 写法代替分支写法 (适用于旧版本 HLS 工具, 新版本几乎推断得很好). 这些变换都能帮助编译器更好地理解代码的并行性, 从而实现更好的 Dataflow 调度效果.